Flink Runtime架构及部署模式
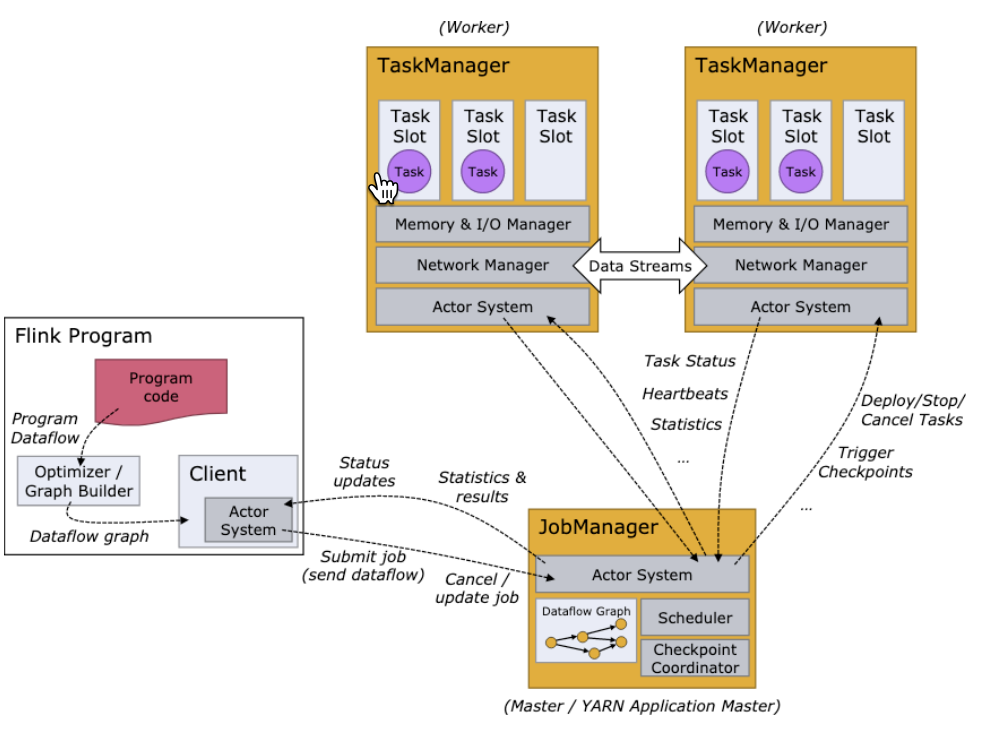
整体架构
JobManager
-
管理节点,每个集群至少一个(可以选择设置多个以保证集群高可用),管理整个集群计算资源,Job管理于调度执行,以及Checkpoint协调。
-
主要行动及组件:
-
Checkpoint Coordinator,根据Checkpoint配置,周期性发起Checkpoint;
-
JobGraph –> Execution Graph,接收Client发送的JobGraph并生成Execution Graph;
-
RPC通信,保持与TaskManager的通信;
-
Job接收,通过Job Dispatch组件接收Client传递的JobGraph;
-
集群资源管理,通过ResourceManager实现;
-
Task部署与调度,TaskManager注册与管理;
-
TaskManager
-
每个集群有多个TM,负责计算资源提供。
-
主要行动及组件:
-
Task任务执行;
-
Network Manager,为算子之间数据传递提供资源;
-
Shuffle Environment管理,为Shuffle操作提供环境;
-
RPC通信,保持与JobManager的通信;
-
和JobManager以及ResourceManager保持心跳连接;
-
TaskManager内存资源管理及节点之间数据交换;
-
在ResourceManager中进行注册;
-
为JobManager提供slot资源;
-
Client
-
本地执行应用main()方法解析JobGraph对象,并最终将JobGraph提交到JobManager运行,同时监控Job执行的状态。
-
主要行动及组件:
-
Application main()方法执行,生成JobGraph,并提交至JobManager;
-
解析并发送应用依赖至JobManager;
-
和JobManager保持RPC通信;
-
Native模式的集群部署;
-
-
Flink任务调度原理
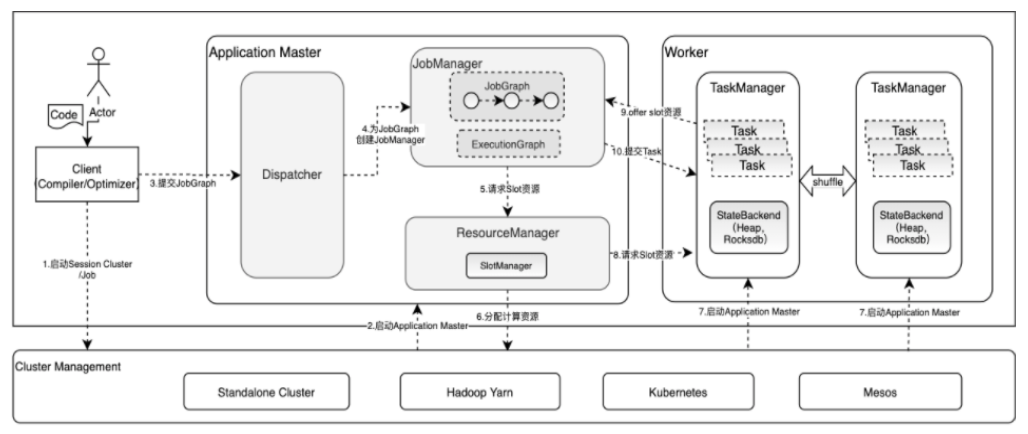
Flink任务从提交到运行
-
用户通过命令bin/flink run -m yarn-cluster提交Job,触发整个集群服务的启动过程;
-
Yarn集群收到用户提交的启动flink集群的申请,选择一个Container启动ApplicationMaster,来管理Flink集群中的进程,并代替Flink进行向外部资源管理器(即Yarn)申请资源;
-
客户端将用户提交的应用程序代码经过本地运行生成JobGraph,然后通过ClusterClient将JobGraph提交到JobManager;
-
JobManager中的Dispatcher组件接收到Client提交的JobGraph对象,然后根据JobGraph启动JobManager RPC服务。JobManager是每个提交的作业都会单独创建的作业管理服务,PerJob部署模式下生命周期和整个作业的生命周期一致;
-
当JobManager启动后,根据JobGraph配置的计算资源向ResourceManager服务申请运行Task实例需要的Slot计算资源;
-
ResourceManager接收到JobManager提交的资源申请后,先判断集群中是否有足够的Slot资源满足作业的资源申请,如果有则直接向JobManager分配计算资源,如果没有则动态地向外部集群资源管理器(即Yarn)申请启动额外的Container以提供Slot计算资源;
-
当向Yarn申请到Container资源后,就会根据ResourceManager的命令启动指定的TaskManager实例;
-
TaskManager启动后会主动向ResourceManager注册Slot信息,即其自身能提供的全部Slot资源;
-
ResourceManager接收到TaskManager中的Slot计算资源,就会立即向该TaskManager发送Slot资源申请,为JobManager服务分配提交任务所需的Slot计算资源;
-
TaskManager接收到ResourceManager的资源分配请求后,TaskManager会对符合申请条件的SlotRequest进行处理,然后立即向JobManager提供Slot资源;
-
JobManager会接收到来自TaskManager的offerslots消息,接下来会向Slot所在的TaskManager申请提交Task实例。TaskManager接收到来自JobManager的Task启动申请后,会在已经分配的Slot卡槽中启动Task线程;
-
TaskManager中启动的Task线程会周期性地向JobManager汇报任务运行状态,直到完成整个任务运行。
运行模式
- 集群部署模式的划分可以根据集群的生命周期和资源隔离,以及程序的main()方法是执行在Client中还是JobManager中,可划分为以下三种模式:
Session模式
-
共享JobManager和TaskManager,所有提交的Job都在一个Runtime中运行;
-
优点:
-
资源充分共享,提升资源利用率;
-
Job在Flink Session集群中管理,运维简单;
-
-
缺点:
-
资源隔离相对较差;
-
非Native类型部署,TM不易扩展,Slot计算资源伸缩性较差;
-
Per-Job模式
-
独享JobManager与TaskManager,为每个Job单独启动一个Runtime;
-
优点:
-
Job和Job之间资源隔离充分;
-
资源根据Job需要进行申请,TM Slots数量可以不同;
-
-
缺点:
-
资源相对比较浪费,JobManager需要消耗资源;
-
Job管理完全交给ClusterManagement,管理复杂;
-
Application模式
-
Application模式的main()运行在Cluster上,而不在客户端,每个Application对应一个Runtime,Application中可以含有多个Job;
-
优点:
-
有效降低带宽消耗和客户端负载;
-
Application实现资源隔离,Application中实现资源共享;
-
-
缺点:
- 仅支持Yarn和K8S两种部署环境;