IoTDB - 系统内存管理 | 数据写入 | 客户端接口
系统内存管理
总内存分配
在同一台机器上部署confignode和datanode节点时可按如下比例将机器内存进行分配
datanode堆内:datanode堆外:confignode堆内:confignode堆外:others=8:3:2:1:2
内存参数配置可在confignode-env.sh和datanode-env.sh文件中进行修改
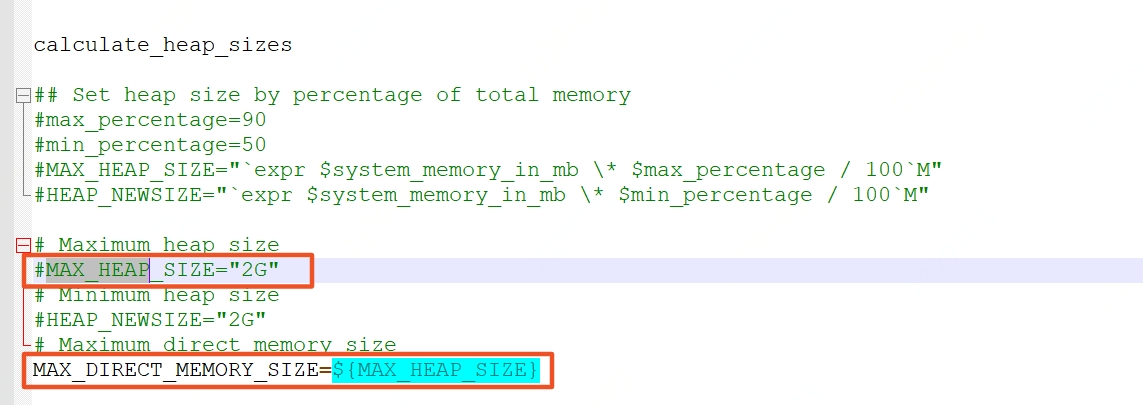
从上到下,逐级分配,每一级不同模块的内存由父模块拆解而来,每一级的比例都由参数控制。
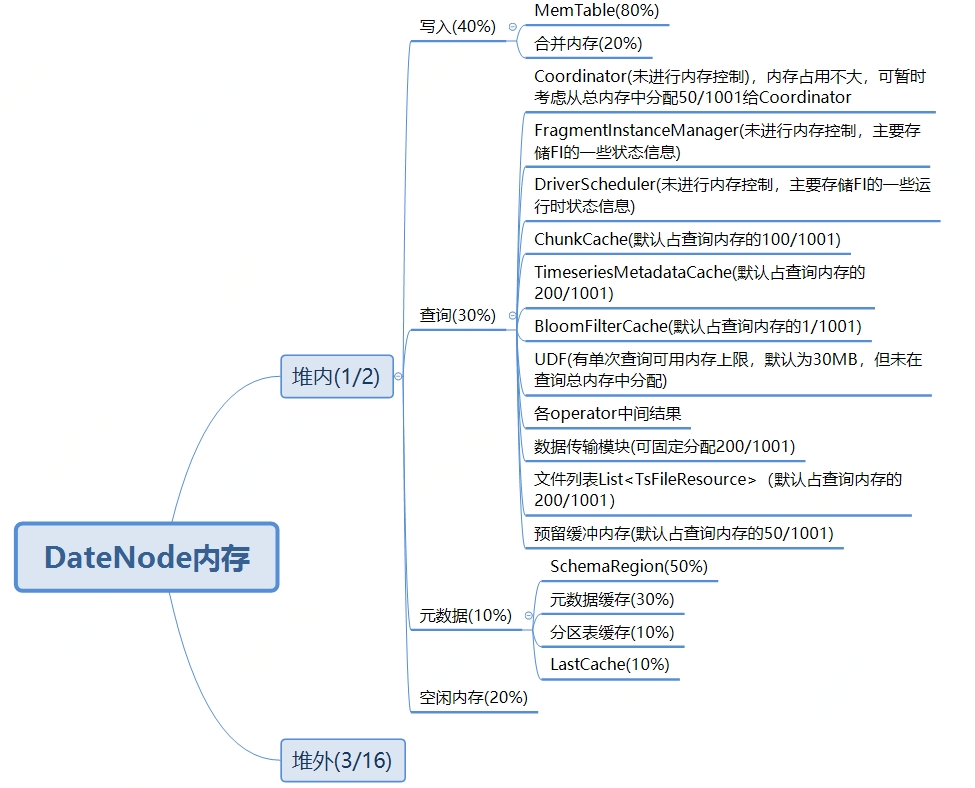
DataNode内存分配
•总体内存分配:【存储引擎:查询:元数据:空闲内存】 write_read_schema_free_memory_proportion=4:3:1:2
•存储引擎内存分配:【Write :Compaction】
storage_engine_memory_proportion=8:2
•查询引擎内存分配:【BloomFilterCache : ChunkCache : TimeSeriesMetadataCache : Coordinator : Operators : DataExchange : timeIndex in TsFileResourceList : others.】chunk_timeseriesmeta_free_memory_proportion=1:100:200:50:200:200:200:50
•元数据内存分配:【分区表缓存:元数据缓存:SchemaRegion:LastCache】schema_memory_allocate_proportion=5:3:1:1
以上所以参数均可在iotdb-datanode.properties中根据实际情况进行调节。
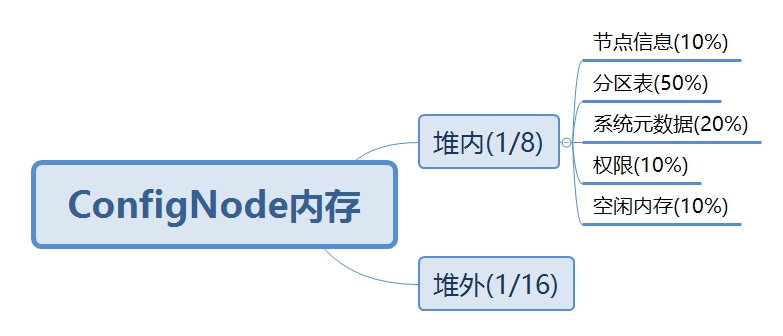
Confignode内存分配
总体内存分配:【节点信息:分区表:系统元数据:权限:空闲内存】
confignode_memory_proportion=1:5:2:1:1
数据写入
IoTDB基于LSMtree的架构进行设计,LSM树的核心思想是放弃部分读能力,换取写入能力的最大化。核心思路其实非常简单,就是假定内存足够大,因此不需要每次有数据更新就必须将数据写入到磁盘中,而可以先将最新的数据驻留在内存中,等到积累到一定程度后,再使用归并排序的方式将内存中的数据合并追加到磁盘队尾。
基于LSM Tree的写入过程:一个数据写入到来之后,先进行WAL的落盘。写WAL是为了恢复,真正的有序写入要将数据写入内存,也就是Mem-Table,然后对Mem-Table进行排序,数据写入到内存之后,就表示写入成功了。当内存数据到达一定规模,就需要写入磁盘,LSM Tree的做法是将要刷磁盘的Mem-Table变成immutable,刷磁盘同时不影响写入请求,在创建一个新的Mem-table。同时对持久化的数据进行合并和索引的建立。
查询逻辑最核心的是要查询索引,首先在内存Mem-table里面查询,然后在immutable Mem-table里面进行查找,然后是磁盘Flie里面进行查找。当然这里有Bloom filter辅助查询。Bloom filter本质就是一个bitmap,每个key数据用k个独立的hash就行计算,填充bitmap,数据查询时候Bloomfilter说没有一定没有,Bloomfilter说有,不一定有,还要继续索引查找。
写入流程
•客户端 C 连接集群任意 DataNode A 发送写入请求
•如果 A 本地没有当前写入数据的分区表缓存,向 ConfigNode 共识组发送写入的设备全路径和时间
•ConfigNode共识组的执行流程
找到此数据对应的数据分区,找到此数据分区对应的 List<DataRegion 共识组>,选择最后一个作为写入的 DataRegion,找到此 DataRegion 共识组对应的一组 DataNode 并返回
•DataNodeA 缓存分区信息,并根据该信息将写入请求转发给 DataNodeB,并携带 DataRegion 共识组信息
•如果DataNode B 本地没有写入序列的元数据,则检查此次写入的序列是否已经在集群注册
如果DataNodeB 本地没有当前存储组的元数据分区表缓存,则向 ConfigNode 共识组发请求,查找写入点的元数据所在的 SchemaRegion 及所在的 DataNode D,B 缓存分区信息,并根据该信息将写入的序列及推断类型发送至 SchemaRegion ,DataNodeB 以 SchemaRegion 返回的信息决定抛错或者在本地注册不存在序列的元数据。
•DataNodeB 将数据添加到共识模块中,写入成功后返回
写入接口
InsertRow
该接口用于写入一个设备中的一行数据(多个物理量),可以写入对齐或非对齐的物理量。
具体流程:
•客户端C连接集群内任意DataNode A发送写入请求
•如果A的ClientRequestHandler接收到写入请求,使用planner转为物理计划InsertRowPlan,传递给Coordinator处理
•A在Coordinator中使用ClusterPlanRouter对写入请求进行路由
•根据路由结果,将写入的物理计划转发给B,并携带DataRegion共识组信息
•B的ClusterRequestHandler接收来自A的物理计划,转给Coordinator处理
•B在Coordinator传递给本地DataRegion执行
•DataRegion若发现本地没有写入序列的元数据,则检查此次写入的序列是否已经在集群注册
•B将请求发送给共识模块,调用consensusLayer中的write方法,写入成功后返回
InsertRows
该接口用于批量写入,将多个Row请求通过一次rpc来进行执行,写入不具有原子性,在返回结果中包含哪些行被成功写入。
批量写入具体流程:
•客户端C连接集群内任意DataNode A发送写入请求
•如果A的ClientRequestHandler接收到写入请求,使用planner转为物理计划InsertRowsPlan,传递给Coordinator处理
•A在Coordinator中使用ClusterPlanRouter对写入请求进行路由
•根据路由结果,分发属于对应DataRegion的子请求,以节点B为例
•B的ClusterRequestHandler接收来自A的物理计划,转给Coordinator处理
•B在Coordinator传递给本地DataRegion执行
•DataRegion若发现本地没有写入序列的元数据,则检查此次写入的序列是否已经在集群注册
•B将请求发送给共识模块,调用consensusLayer中的write方法,写入成功后返回
InsertTablet
该接口用于写入一个设备中的多个数据点,每个数据点包含设备中的物理量以及对应的时间戳和值,推荐使用该方法进行写入,写入不具有原子性。
InsertMultiTablets
该接口用于批量写入,将多个Tablet请求通过一次rpc来执行,写入不具有原子性,在返回结果中包含哪些行被成功写入。
InsertRowsOfOneDevice
该接口用于同一个设备下的多行写入,相比于InsertRows,减少了devicePath的重复网络传输开销,写入不具有原子性。
客户端接口
IoTDB的客户端和服务器通信采用了跨语言的 RPC 框架 Thirft,理论上 Thrift 能生成的语言都能支持。但是直接用 Thrift 生成的代码对数据库使用者不太友好,所以IoTDB在生成代码的基础上,包装出来了自己的各种客户端接口,这种接口对用户就比较友好了。
JDBC
和标准 JDBC 的使用方式一样,需要加载数据库驱动类,建立连接,建立 Statement,通过 Statement 执行语句,对于非查询来说,可以批量执行减少网络传输次数。
public static void main(String[] args) throws ClassNotFoundException, SQLException {
Class.forName("org.apache.iotdb.jdbc.IoTDBDriver");
try (Connection connection = DriverManager
.getConnection("jdbc:iotdb://127.0.0.1:6667/", "root", "root");
Statement statement = connection.createStatement()) {
// 创建存储组
statement.execute("SET STORAGE GROUP TO root.statistic");
// 创建时间序列
statement.execute("CREATE TIMESERIES root.statistic.device1.s1 WITH DATATYPE=INT64, ENCODING=RLE, COMPRESSOR=SNAPPY");
statement.execute("CREATE TIMESERIES root.statistic.device1.s2 WITH DATATYPE=INT64, ENCODING=RLE, COMPRESSOR=SNAPPY");
statement.execute("CREATE TIMESERIES root.statistic.device1.s3 WITH DATATYPE=INT64, ENCODING=RLE, COMPRESSOR=SNAPPY");
// 在客户端积累一批更新语句
for (int i = 0; i <= 100; i++) {
statement.addBatch("insert into root.statistic.device1(timestamp, s1, s2, s3) values("+ i + "," + 1 + "," + 1 + "," + 1 + ")");
}
// 执行
statement.executeBatch();
statement.clearBatch();
// 查询
ResultSet resultSet = statement.executeQuery("select * from root where time <= 10");
// 打印结果集
ResultSetMetaData metaData = resultSet.getMetaData();
int columnCount = metaData.getColumnCount();
while (resultSet.next()) {
for (int i = 1; i < columnCount; i++) {
System.out.print(resultSet.getString(i));
System.out.print(" ");
}
System.out.println();
}
}
}
Java 原生接口 Session
对于数据写入,SQL 解析就占了 70% 耗时。于是提供了一个原生的 NoSQL 接口(Session),相比于 JDBC 更高效。
insertRecordsOfOneDevice(String deviceId,
List<Long> times,
List<List<String>> measurementsList,
List<List<TSDataType>> typesList,
List<List<Object>> valuesList )
这个接口就对应一个 insert 语句,一次可以写入一个设备多个时间戳多个测点的值,其中值的类型需要和注册的类型保持一致,如果没注册过则自动注册此类型。
insertTablet(Tablet tablet, boolean sorted)
String deviceId = "root.statistic.`1.2.156.156.11.20.156474992001050684`";
List<MeasurementSchema> schemaList = new ArrayList<>();
schemaList.add(new MeasurementSchema("s1", TSDataType.INT64));
schemaList.add(new MeasurementSchema("s2", TSDataType.INT64));
schemaList.add(new MeasurementSchema("s3", TSDataType.INT64));
Tablet tablet = new Tablet(deviceId, schemaList, 100);
tablet.initBitMaps();
long timestamp = System.currentTimeMillis();
for (long row = 0; row < 100; row++) {
int rowIndex = tablet.rowSize++;
tablet.addTimestamp(rowIndex, timestamp);
for (int s = 0; s < 3; s++) {
long value = new Random().nextLong();
// mark null value
if (row % 3 == s) {
tablet.bitMaps[s].mark((int) row);
}
tablet.addValue(schemaList.get(s).getMeasurementId(), rowIndex, value);
}
if (tablet.rowSize == tablet.getMaxRowNumber()) {
session.insertTablet(tablet, true);
tablet.reset();
}
timestamp++;
}
if (tablet.rowSize != 0) {
session.insertTablet(tablet);
tablet.reset();
}
一个Tablet 是一个设备多个时间戳多个测点的值。这里要注意,每个测点在每个时间戳都需要有值,不能有空的。sorted 表示是否时间戳是递增的,如果能保证递增,可以设置为 true,否则还会再排个序。如果只计算执行时间,这个接口是最高效的,因为里边使用了原始类型的数组,避免了装箱。
和insertRecordsOfOneDevice接口相比,其具有更快的写入速度与占用更少的网络带宽的优点。经验证,写入一个设备的一个测点的1万个数据点,insertRecordsOfOneDevice接口需要10s,而insertTablet接口只需要20ms,相差500倍的写入速度。
此外还有 insertTablets 和 insertRecords 两种,其实就是以上几种接口的批量的形式。
Session 的查询结果集是 SessionDataSet,这个结构提供的 hasNext 和 next 方法把每一行数据都转化成了 RowRecord 这个结构,如果客户端还需要做其他转化,这个结构就多余了。这时候可以通过 SessionDataSet.iterator()得到一个迭代器,这个迭代器的访问数据的方式和 JDBC 的 ResultSet 是一样的,直接从字节数组里拿数据,比 RowRecord 更高效。
连接池 SessionPool
连接池的接口和 Session 基本一样,但是连接池可以供多线程使用,而且可以屏蔽连接异常等问题。使用连接池唯一一点需要注意的是,查询得到的结果集使用完需要返还给连接池(调用连接池的 closeResultSet 方法),不然连接会被占用,无法得到新的连接就报超时了。